本章学习主要是针对,给定样本及其已知类别,通过机器学习获取到各类特征。如何训练分类模型,并通过分类模型预测未知样本的类别。
问题背景:假设你是渔业生产的从业者,可以通过观察水的颜色调控水质。比如浅绿色的水质为1级,灰蓝色的水质为2级等。如果我们使用计算机视觉监控,需要计算机通过图像处理来判定水的颜色,以及其对应的水质级别。本案例选择采用颜色矩来提取水样颜色的各个特征,作为训练特征。
一、挖掘目标
1、通过水样图像,自动判别出该水样的水质类别。
此为多分类问题,分类结果为多级水质。
二、数据抽取
1) 拍摄水样图像,从中提取反映图像本质的关键指标。
2) 图像特征主要包括颜色特征、纹理特征、形状特征、空间关系特征等。这里我们选取颜色特征。
如下图为采集的水样图像原始数据(此时并未提取特征)
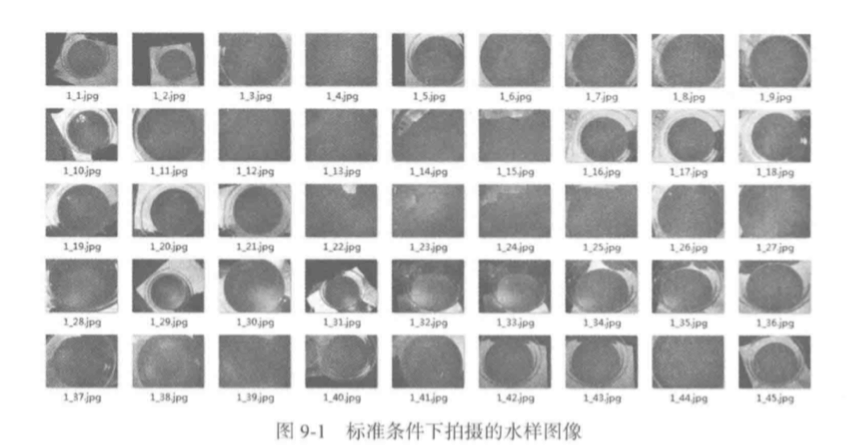
三、数据预处理
1、 图像切割
采集到的水样图像包含了盛水容器等,为了提取到水色的特征,需要提取图像中央部分具有代表意义的图像,具体实施是提取水样图像中央101*101像素图像。如图切割:

2、 特征提取
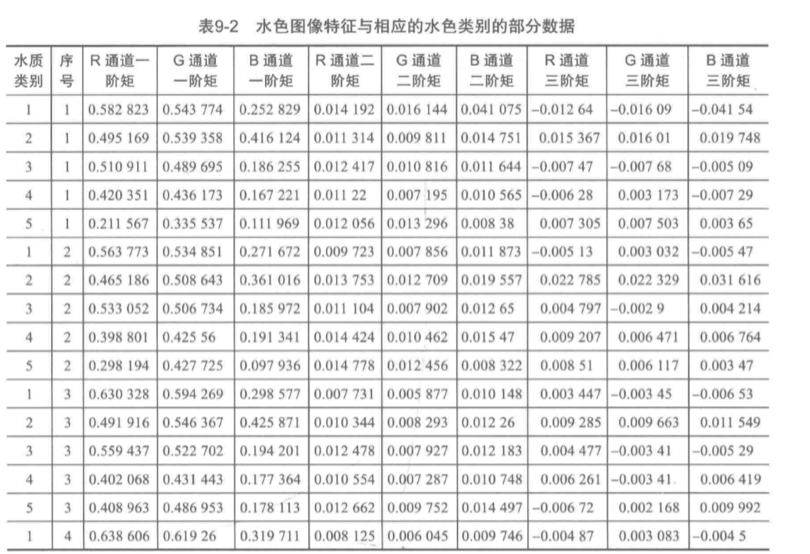
本案例我们采用颜色矩来提取水样图像特征。
颜色矩是一种简单有效的颜色特征表示方法:
1) 一阶颜色矩(一阶原点矩)——均值,反映图像的敏感程度
Ei=1N∑j=1Npij
其中,
Ei
是第
i
个颜色通道的一阶颜色矩,颜色通道对于RGB颜色空间,则为R通道、G通道、B通道;
pij
是第
j
个像素的第
i
个颜色通道的颜色值;
N
为像素个数.
2) 二阶颜色矩(二阶中心距)——标准差,反映图像颜色分布范围
σi=1N∑j=1N(pij−Ei)2−−−−−−−−−−−−−−⎷
其中,
σi
实在第
i
个颜色通道的二阶颜色矩,
Ei
是第
i
个颜色通道的一阶颜色矩。
3) 三阶颜色矩(三阶中心距)——斜度,反映图像颜色对称性
si=1N∑j=1N(pij−Ei)3−−−−−−−−−−−−−−⎷3
其中,
si
是在第
i
个颜色通道的三阶颜色矩,
Ei
是在第
i
个颜色通道的一阶颜色矩。
四、模型构建
实际这是一个多分类问题,分类模型也比较多,这里选择SVM算法模型模型详细介绍可点击链接,模型构建过程如下。这里稍微简单的说一下机器学习的过程,首先切分数据集为训练集和测试集(也可以是独立的两个数据集),然后我们选择合适的算法,每种算法模型都可以有多种参数,但是确定什么样的参数才能解决我们当前的问题,这就需要训练集一个一个的带入到算法模型里然后一步一步的调整到合适的参数获得模型。最后我们需要把测试集代入到训练好的模型里,评估一下这个模型是不是在任何该问题的数据下都能够准确的得到预测结果。评估分类模型的指标也有很多(参考什么是数据挖掘),本章我们选择混淆矩阵。
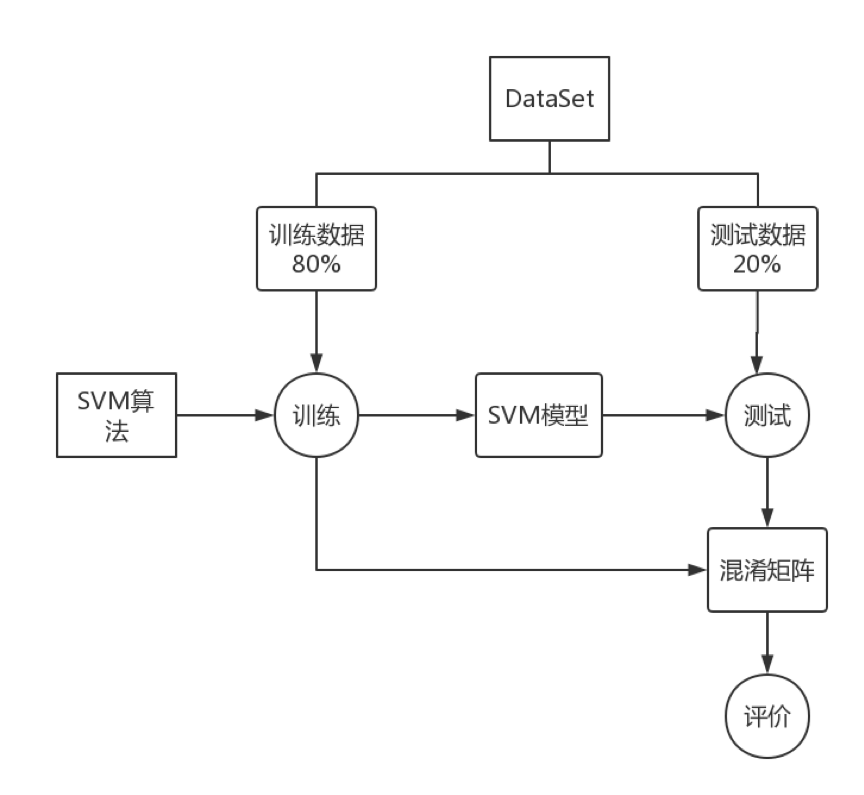
按照上图的步骤我们进行代码的编写:
1、 python实现数据划分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import pandas as pd
inputfile='../data/moment.csv'
outputfile1='../tmp/cm_train.xls'
outputfile2='../tmp/cm_test.xls'
data=pd.read_csv(inputfile,encoding='gbk')
data=data.as_matrix()
from numpy.random import shuffle
shuffle(data)
data_train=data[:int(0.8*len(data)), :]
data_test=data[int(0.8*len(data)):, :]
x_train=data_train[:, 2:]*30
y_train=data_train[:, 0].astype(int)
x_test=data_test[:, 2:]*30
y_test=data_test[:, 0].astype(int)
|
2、 python使用SVM算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from sklearn import svm
model=svm.SVC()
model.fit(x_train, y_train)
import pickle
pickle.dump(model, open('../tmp/svm.model','wb'))
from sklearn import metrics
cm_train=metrics.confusion_matrix(y_train, model.predict(x_train))
cm_test=metrics.confusion_matrix(y_test, model.predict(x_test))
pd.DataFrame(cm_train, index = range(1, 6), columns = range(1, 6)).to_excel(outputfile1)
pd.DataFrame(cm_test, index = range(1, 6), columns = range(1, 6)).to_excel(outputfile2)
|
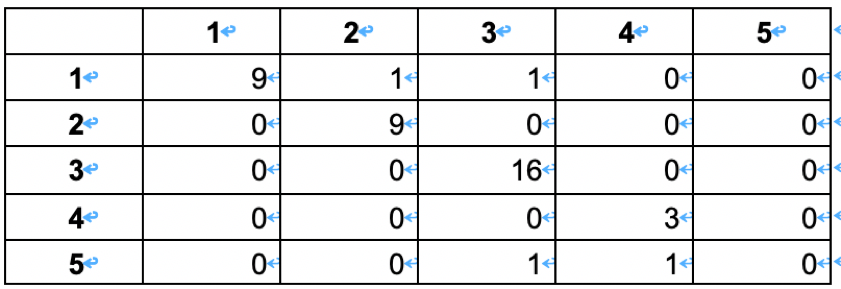
这里使用模型的混淆矩阵所为评判标准:
1、模型混淆矩阵(训练集建模后的回判)。分类准确率为96.91%,分类效果较好。
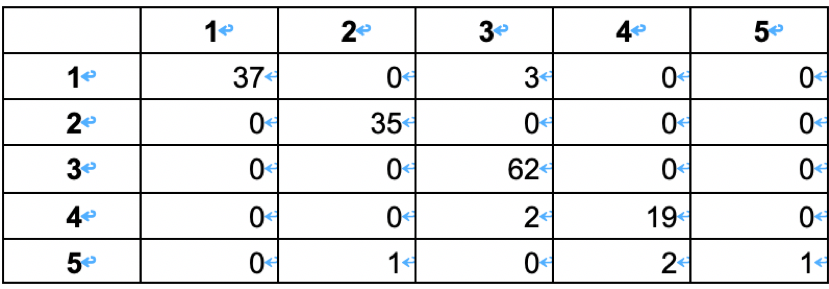
3、 水质评价的混淆矩阵(测试集代入建好的模型)。分类准确率为95.12%,说明水质评价模型对于新增的谁知图像的分类效果较好。