数据挖掘实战2-航空公司客户价值分析
本次学习我们仍然遵循“什么是数据挖掘”文章中的研究方法对航空公司消费客户进行聚类。本章学习重点是如何标准化处理数据,使用k-means聚类,明白聚类和分类的区别。
问题背景:假设你是航空公司的,如何针对不同的顾客进行活动的推销,维持经常飞行的顾客,吸引新的顾客。这就需要我们对顾客进行聚类,那么什么是聚类,为什么不叫分类。因为分类是有监督的学习,聚类是无监督的学习。我们可以对比实战1,可以发现在实战1中我们的数据里明确是有分类的结果供模型去学习的(两个分类结果,一个是偷电用户,一个是非偷电用户),但是本章学习中我们并不清楚我们都有哪几类用户,要把数据分为哪几类。所以一个是分类,一个是聚类。
一、挖掘目标
1、借助航空公司客户数据,对客户进行聚类
2、对不同的客户类别进行特征分析,比较不同类别的客户价值
二、数据抽取
1、客户个人信息,包括会员卡号、入会时间、性别、年龄等
2、客户乘机记录,包括,飞行次数、飞行时间、乘机间隔、平均折扣等
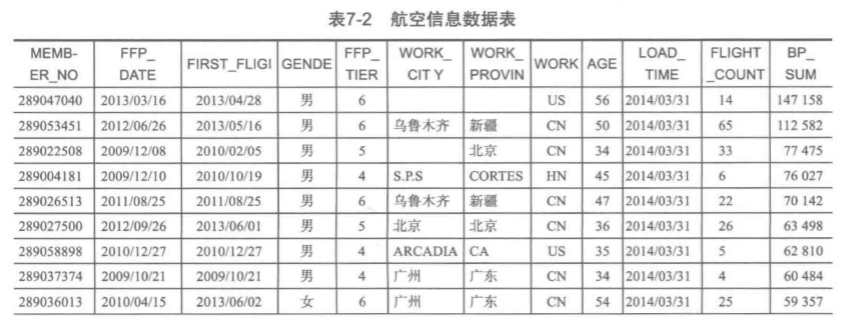
如图是实际采集的数据:
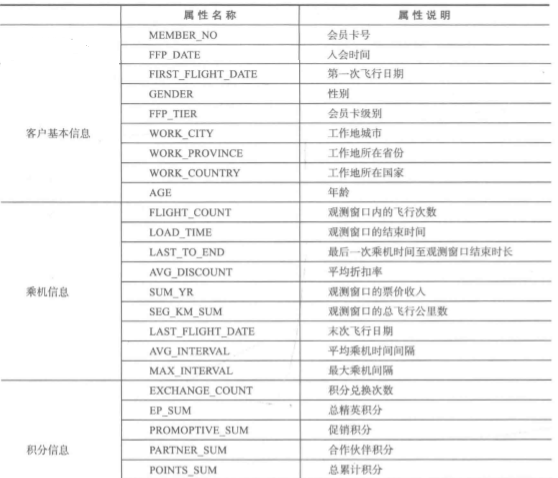
属性值意义参考表:
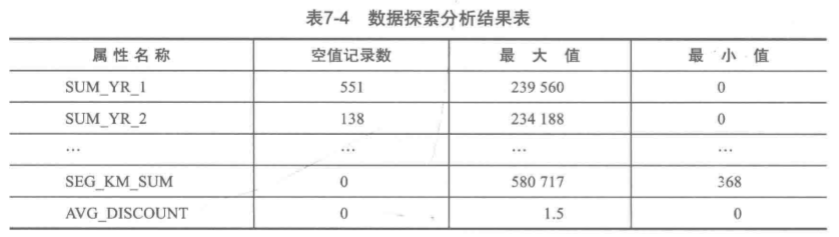
三、数据探索:统计分析
1、对数据进行缺失值分析与异常值分析
2、查找每列属性的空值个数、最大值、最小值.
使用python进行数据的统计,源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import pandas as pd
datafile='../data/air_data.csv'
result_file='../tmp/explore.xls'
data=pd.read_csv(datafile,encoding='utf-8')
explore=data.describe(percentiles= [],include='all').T
explore['null']=len(data)-explore['count']
explore=explore[['null','max','min']]
explore.columns = [u'空值表',u'最大值',u'最小值']
'''这里只选取部分探索结果。
dscribe()函数自动计算的字段有count(非空值表),unique(唯一值数),top(频数最高者),
freq(最高频数)、mean(平均值),std(方差),min(最小值),50%(中位数),max(最大值)'''
explore.to_excel(result_file)
|
统计结果如下:
四、数据预处理
1、数据清洗
1、丢弃票价为空的记录
2、丢弃票价为0,但平均折扣率不为0,总飞行公里数大于0的记录。(脏数据)
python进行如上数据清洗:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import pandas as pd
datafile='../data/air_data.csv'
cleanedfile='../tmp/data_cleanedxls'
data=pd.read_csv(datafile,encoding='utf-8')
data=data[data['SUM_YR_1'].notnull()&data['SUM_YR_2'].notnull()]
index1=data['SUM_YR_1']!=0
index2=data['SUM_YR_2']!=0
index3=(data['SEG_KM_SUM']==0)&(data['avg_discount']==0)
data=data[index1|index2]
data.to_excel(cleanedfile)
|
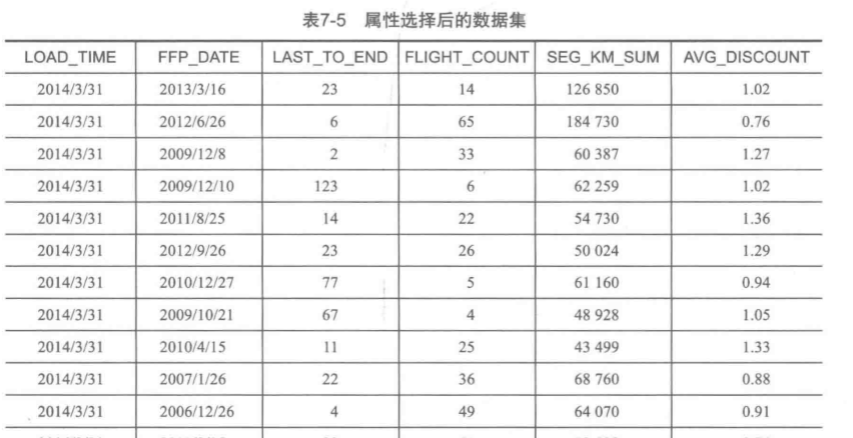
2、数据规约
原始数据属性太多,我们使用LRFMC模型,选择6个与LRFMC模型相关属性指标,以供接下来构造LRFMC模型。如下图所示:
3、数据变换
1、构建LRFMC这五个指标如下公式(都在观测窗口(某个约定的时间段)内进行计算):
(1)会员入会时间:L=LOAD_TIME-FPP_DATE
(2)最后一次乘车时间到结束的月数:R=LAST_TO_END
(3)飞行次数:F=FLIGHT_COUNT
(4)总飞行公里数:M=SEG_KM_SUM
(5)平均折扣率C=AVG_DISCOUNT
2、由数据探索时候,统计可知,这5个指标实际上取值范围相差较大。我们一般为了消除数量级数据带来的影响,需要对数据进行标准化处理(详情请点击这里)。
python实现数据标准化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import pandas as pd
datafile='../data/zscoredata.xls'
zscoredfile='../tmp/zscoreddata.xls'
data=pd.read_excel(datafile)
data=(data-data.mean(axis=0))/(data.std(axis=0))
data.columns=['Z'+i for i in data.columns]
data.to_excel(zscoredfile,index=False)
|
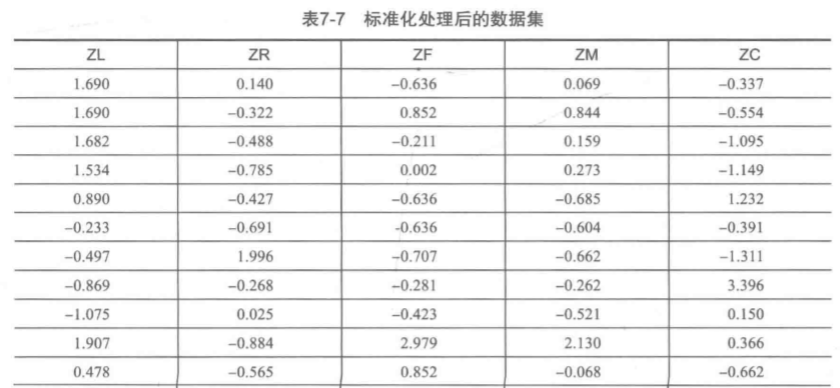
由上面两步,一个属性规约,一个数据标准化后,得到的数据如下图所示:
五、模型构建
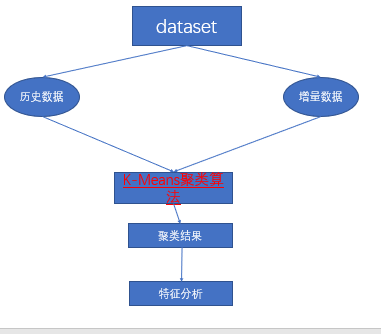
到此为止,我们已经获取到相对适合处理的干净数据了,本步我们选用k-means聚类算法(详情请点击这里)进行聚类。实际上聚类完成后我们会获取到每一类的中心,这个时候我们可以把它保存下来,可以用来分类未知的增量数据。
我们进行聚类的整体过程如下图,用历史数据进行K-means聚类获得聚类的中心点,然后再用增量数据在中心点上进行分类,这里简单提一下。聚类实际上用的就是距离相近的属于一类。
按照上面的步骤我们对数据进行python聚类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import sys
reload(sys)
sys.setdefaultencoding('ISO-8859-1')
import pandas as pd
from sklearn.cluster import KMeans
inputfile='../tmp/zscoreddata.xls'
outputfile='../tmp/kmeans_result.xls'
k=5
data=pd.read_excel(inputfile)
kmodel=KMeans(n_clusters=k,n_jobs=4)
kmodel.fit(data)
r1=pd.Series(kmodel.labels_).value_counts()
r2=pd.DataFrame(kmodel.cluster_centers_)
r=pd.concat([r2,r1],axis=1)
r.columns=list(data.columns)+[u'类别数目']
r.to_excel(outputfile)
|
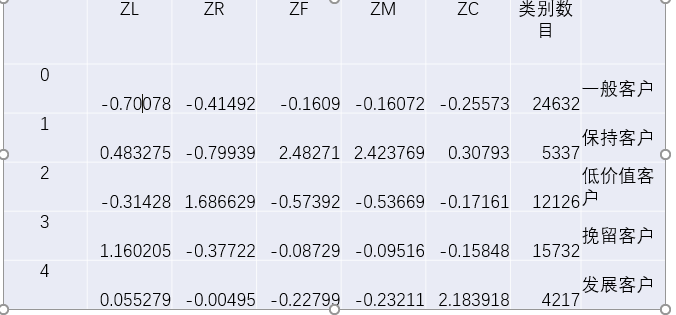
我们这里设置聚类的数量为5类,然后会得到每一个属性每一类的聚类中心值,如下图:
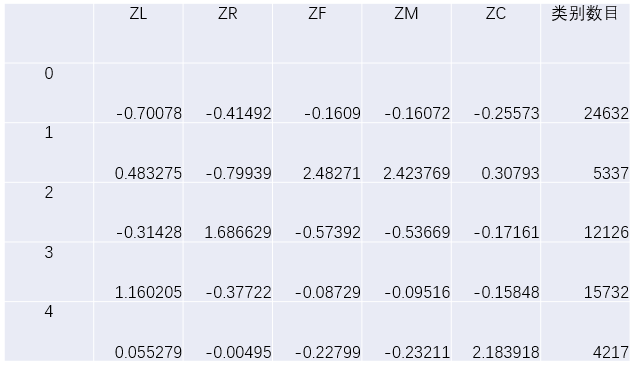
六、特征分析
为了便于可视化分析,我们使用python将结果绘制成雷达图(接上面的代码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import matplotlib.pyplot as plt
import numpy as np
plt.style.use('ggplot')
plt.rcParams['font.sans-serif']='simkai'
plt.rcParams['axes.unicode_minus'] = False
labels=np.array(data.columns)
dataLenth=5
N=len(r2)
angles=np.linspace(0,2*np.pi,N,endpoint=False)
data=pd.concat([r2,r2.ix[:,0]],axis=1)
angles=np.concatenate((angles,[angles[0]]))
fig=plt.figure(figsize=(6,6))
ax=fig.add_subplot(111,polar=True)
for i in range(0,5):
j=i+1
ax.plot(angles,data.ix[i,:],'o-',linewidth=2,label="Customers{0}".format(j))
ax.set_thetagrids(angles *180/np.pi,labels)
ax.set_title("Customers Analysis",va='bottom',fontproperties="SimHei")
ax.set_rlim(-1,2.5)
ax.grid(True)
plt.legend()
plt.show()
|
雷达图如下:
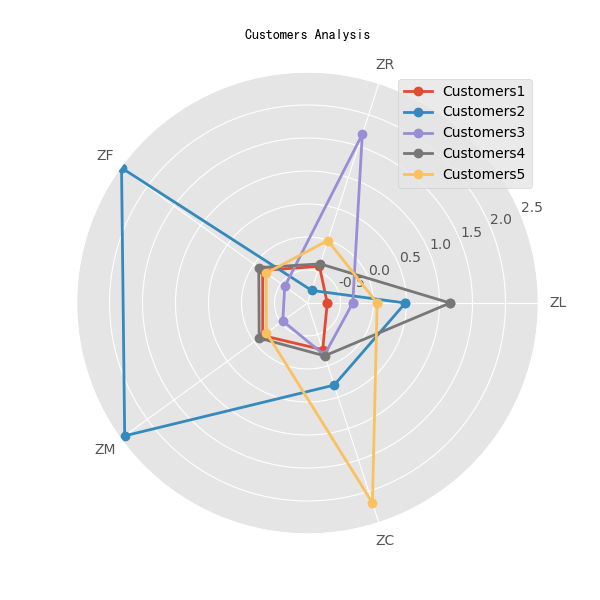
根据特征描述表,定义5种客户:
1、重要保持客户:
平均折扣率(C)较高,最近乘坐航班时间(R)低,乘坐次数(M)或者里程(M)较高
2、重要发展客户:
平均折扣率(C)较高,最近乘坐航班时间(R)低,但入会时间(L)短,乘坐次数(F)或乘坐里程(M较低)
3、重要挽留客户:
过去平均折扣率(C)较高,乘坐次数(F)或里程(M)较高,但长时间没有乘坐(R)
4、一般与低价值客户
平均折扣率(C)较低,较长时间没有乘坐本航班(R),乘坐次数h(F)或里程(M)较低,入会时间短(L)